

All in all... 
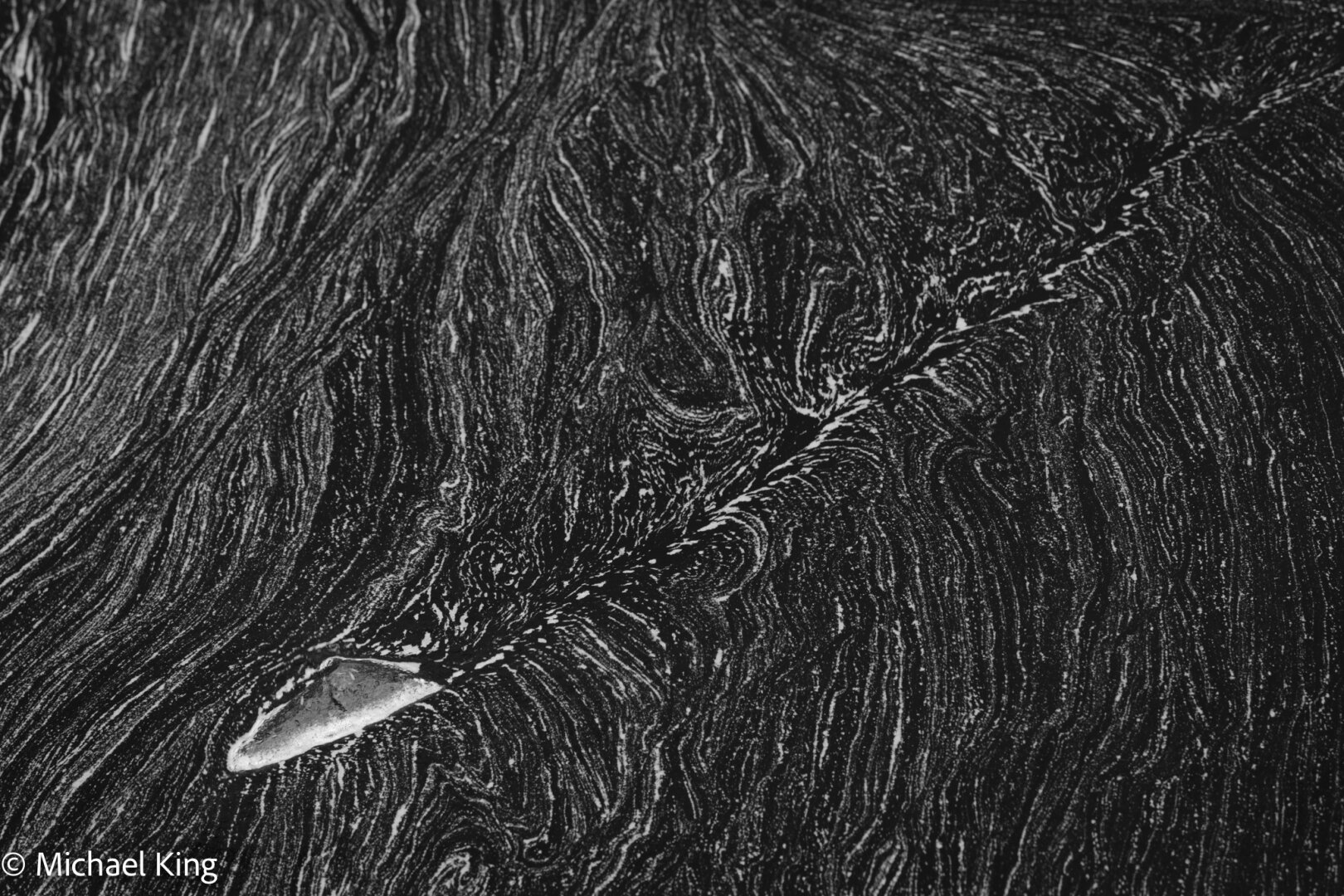
 "Another Brick in the Wall, Part Two" - Pink Floyd
"Another Brick in the Wall, Part Two" - Pink Floyd 
https://youtube.com/watch?v=HrxX9TBj2zY
#portland #oregon #pdx #pnw #photos #photography #mobilephotography #digitalphotography #iphone #shotoniphone #iphoneography #smartphoneography #fediverse #pixelfed #abstract #textures #patterns #brick #bricks #walls #pinkfloyd #thewall
"Another Brick in the Wall, Part Two" - Pink Floyd https://youtube.com/watch?v=HrxX9TBj2zY
#portland #oregon #pdx #pnw #photos #photography #mobilephotography #digitalphotography #iphone #shotoniphone #iphoneography #smartphoneography #fediverse #pixelfed #abstract #textures #patterns #brick #bricks #walls #pinkfloyd #thewall














 0, #0000 5px 50px;
background:
/* shadows */
repeating-linear-gradient(45deg, var(--s)),
repeating-linear-gradient(-45deg, var(--s)),
/* main pattern */
repeating-linear-gradient(45deg, var(--c)),
repeating-linear-gradient(-45deg, var(--c));
background-blend-mode:
multiply, multiply, lighten
}
.card:nth-child(1) {
--c: #847971 0 10px, #938981 0 20px,
#9e938a 0 30px, #a89c93 0 40px, #bfb6ab 0 50px
}
.card:nth-child(2) {
--c: #333 0 10px, #555 0 20px,
#c55 0 30px, #ccc 0 40px, #eee 0 50px
}")










 Greg Cocks
Greg Cocks 








