Recent searches
Search options

#vlm



 Greg Cocks
Greg Cocks Satellite Data Study Pinpoints Areas Sinking And Rising Along California Coast
--
https://phys.org/news/2025-02-satellite-areas-california-coast.html <-- shared technical article
--
https://dx.doi.org/10.1126/sciadv.ads8163 <-- shared paper
--
#GIS #spatial #mapping #sealevel #sealevelrise #subsidence #model #modeling #SLR #coast #coastline #verticallandmotion #VLM #California #climatechange #planning #policy #remotesensing #groundwater #pumping #risk #hazard #infrastructure #damage #wastewater #injection #tidegauge #dynamic #spatialanalysis #spatiotemporal #numericmodeling #uplift #projections #flood #flooding #mitigation #satellite #ocean #marine
@nasa

 with uncertainties, California")



@gilesgoat @llamasoft_ox is the #VLM a library you use between multiple games? How much relation does it have to the original Trip-a-Tron I played with on my #atarist?

Une goutte d'eau
Ce monde,
À quoi le comparer ?
À la goutte qui tombe
Du bec de l'oiseau d'eau
Et réfléchit le clair de lune. ~ Dōgen Zenji
Fugacité du monde. Fugacité de la vie de cet être conscient qui perçoit le monde. L'existence en ce monde comme la goutte d'eau qui vient tomber du bec d'un héron et qui s'en va rejoindre l'étang, le conglomérat de toutes les gouttes d'eau. Et dans cette chute qui ne dure que quelques instants, le reflet de la lune habite la transparence de la goutte d'eau.
Notre existence peut sembler infinitésimale tant dans l'espace et dans le temps. Pour autant, elle peut refléter la lumière de l'Éveil.
Ne plus être cette seule goutte prise dans les turbulences de la chute, mais être l'étang et l'oiseau d'eau qui contemple le grand calme de l'étang dans l'aube brumeuse.
.
.
.
[D'après Bai Wenshu]
.
#pensée #penséedujour #penséepositive #bienveillance #inspiration #optimisme #citation #philosophie #calme #contemplation #immobilite #zazen #meditation #Montpellier #VLM #photo #art #philosophy


Hugging Face has introduced two new models in its SmolVLM series, which it claims are the smallest Vision Language Models (VLMs) to date.
https://www.computing.co.uk/news/2025/ai/hugging-face-claims-world-s-smallest-vision-language-models
Projections Of Multiple Climate-Related Coastal Hazards For The US Southeast Atlantic
--
https://doi.org/10.1038/s41558-024-02180-2 <-- shared paper
--
#GIS #spatial #mapping #coast #coastal #water #hydrology #risk #hazard #VLM #VerticalLandMotion #SeaLevel #SealLevelRise #SLR #climatechange #extremeweather #US #USA #SoutheastAtlantic #Atlantic #storm #stormsurge #erosion #groundwater #flood #flooding #subsidence #society #societal #cost #infrastructure #economics #saltwater #property #value #beaches #saltwaterintrusion





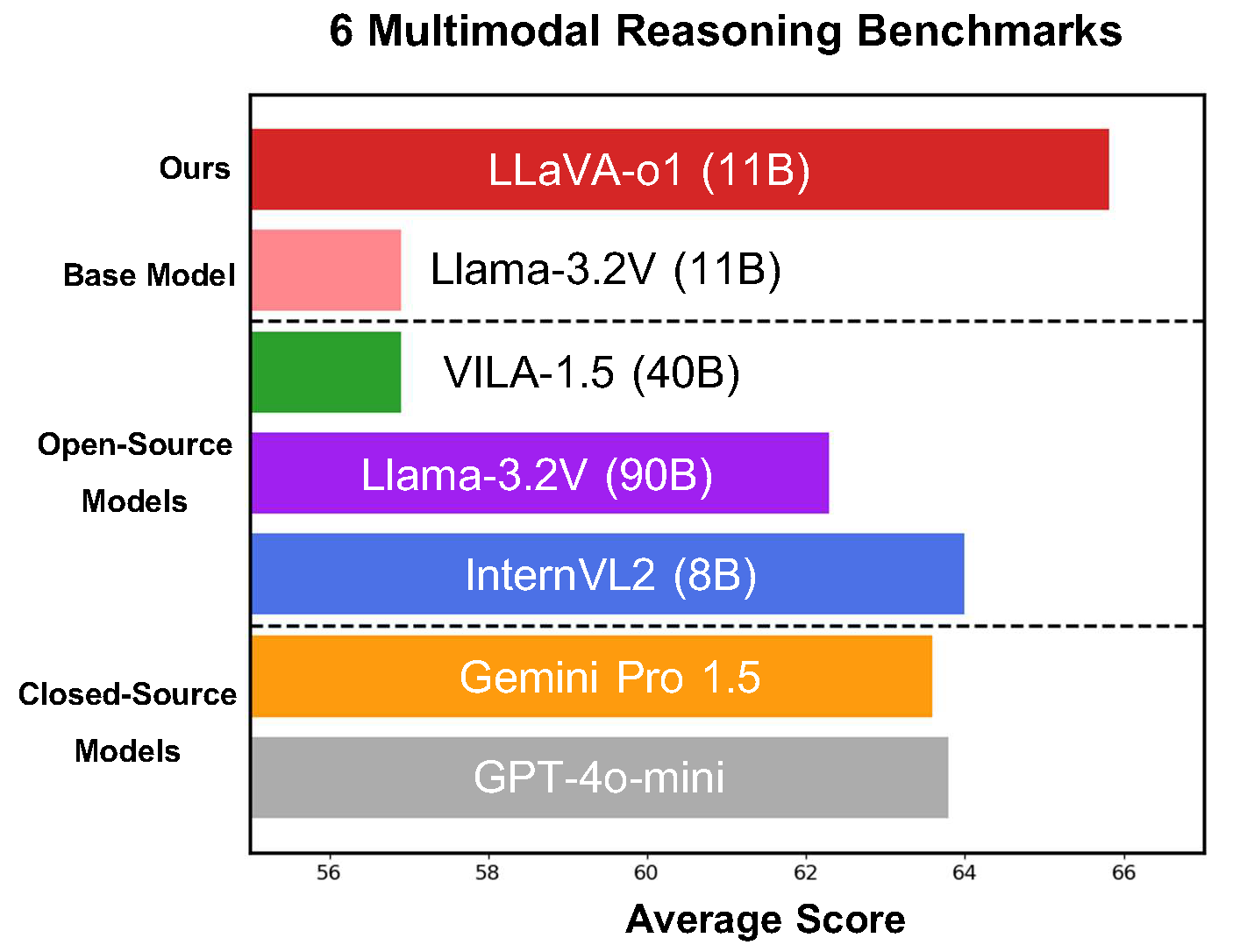
Breakthrough in Visual Language Models and Reasoning 
 #LLaVAo1 pioneers systematic visual reasoning capabilities:
#LLaVAo1 pioneers systematic visual reasoning capabilities:
• First #VLM to implement spontaneous step-by-step analysis like #GPT4
• New 11B model surpasses #Gemini15pro & #Llama32 performance
• Excels on 6 multimodal benchmark tests
• Breaks down complex problems into structured analysis stages
 Key Features:
Key Features:
• Problem outline creation
• Image information interpretation
• Sequential reasoning process
• Evidence-based conclusions
• Handles science & reasoning challenges
 Technical Specs:
Technical Specs:
• Based on #opensource architecture
• Pretrained weights available on #HuggingFace
• 11B parameter model size
• Supports multiple reasoning domains
 Paper available: https://arxiv.org/abs/2411.10440
Paper available: https://arxiv.org/abs/2411.10440 Project repository: https://github.com/PKU-YuanGroup/LLaVA-o1
Project repository: https://github.com/PKU-YuanGroup/LLaVA-o1

Earlier this year I wrote about my handwriting #OCR workflow. I wanted to reduce the friction in this flow so I spent some time building a telegram bot that uses #VLM models to OCR my hand writing. Introducing AnnoMemo which is open source and easyish to self-host. Currently it uses remote models but I'm planning to integrate Qwen2-VL 2B which a) understands my handwriting perfectly and b) runs on my desktop GPU. Considering providing a managed service too https://brainsteam.co.uk/2024/11/3/03-annomemo-telegram-bot/

Photo of the Day 1st November 2024.
PH-BDT, Boeing 737-406, KLM, being pushed back from Gate 24 at Manchester Airport, some time in the 1990s.
On This Day 1st November 1993.
F-GIJT, Airbus A300B4-103, Air Inter, under tow at Paris Orly, 1st November 1993.
On This Day 1st November 1994.
OO-VLN, Fokker F50, VLM, taxiing out to Runway 27 at London City Airport, 1st November 1994.https://mancavgeek.co.uk/2024/11/01/photo-of-the-day-1st-november-2024/




VLM — арт эксперты
Всем привет, меня зовут Арсений, я DS в компании Raft, и сегодня я расскажу вам про VLM. Большие языковые модели уже стали частью нашей жизни и мы применяем, чтобы упростить современную рутину, а так же используем их для решения бизнес задач. Недавно вышло новое поколение vision transformer моделей, которые заметно упростили анализ изображений, из какой бы сферы эти изображения не были. Особенно заметным был сентябрьский релиз Llama-3.2-11b, и не только потому что это первая vision модель от Llama, сколько потому, что с ней вместе вышло целое семейство моделей, включая маленькие на 1B и 3B параметров. А как вы знаете, меньше, значит юзабельнее.

A new study published on arXiv reveals fundamental issues in the visual reasoning abilities of leading AI vision-language models (VLMs) from OpenAI, Google, and Meta. #AI http://dlvr.it/TFpXr8 #AI #ArtificialIntelligence #VLM

VLM в Нейро: как мы создавали мультимодальную нейросеть для поиска по картинкам
Сегодня у Поиска большое обновление. Например, ответы Нейро теперь будут появляться сразу в поисковых результатах — для тех запросов, где это полезно и экономит время. Но в рамках этой статьи нас интересует другая часть обновления: Нейро поможет найти ответы в Поиске по картинкам и в Умной камере — с помощью новой мультимодальной модели Яндекса. Пользователь может не только узнать, что изображено на картинке, но и задать вопрос по каждой её детали. Например, гуляя по музею, можно сфотографировать натюрморт голландского живописца и спросить, что символизирует тот или иной предмет на картине. Меня зовут Роман Исаченко, я работаю в команде компьютерного зрения Яндекса. В этой статье я расскажу, что такое визуально‑текстовые мультимодальные модели (Visual Language Models или VLM), как у нас в Яндексе организован процесс их обучения и какая у них архитектура. Вы узнаете, как Нейро работал с картинками и текстами раньше, и что изменилось с появлением VLM.

Mistralai releases pixtral-12b on Twitter with magnet link! Someone put it on Huggingface for easier download. lol #multimodal #VLM #LLM #ML #AI
https://x.com/mistralai/status/1833758285167722836
https://huggingface.co/bullerwins/pixtral-12b-240910
Does anyone have a recommendation for #LlamaCPP alternative to run recent vision language models on Apple Silicon? Llama.cpp doesn't support any of the recent #VLM such as Qwen2-VL, Phi-3.5-vision, Idefics3, InternVL2, Yi-VL, Chameleon, CogVLM2, GLM-4v, etc.
Minicpm-v 2.6 is the only recent model that was added. Maybe time to move on. :( #LLM #multimodal #AppleSilicon #MacOS #ML #AI

 Hacker News
Hacker News Cradle: Empowering Foundation Agents Towards General Computer Control
https://baai-agents.github.io/Cradle/
#ycombinator #Agent #VLM #GCC #Cradle #Agent_Framework #GPT_4V
Does anyone have a suggestion on how to run newer/more capable vision language models on Mac like XComposer2, CogVLM2-Chat, InternVL-Chat, Qwen-VL, DeepSeek-VLm, Phi3-V, etc? Vision language support for newer models are stalled in llama.cpp, so it seems impossible to find an option on Mac. Even with Torch MPS support because flash attention is not available for Apple Silicon! #LLM #VLM #ML #AI






 Vegan Land Movement
Vegan Land Movement
Removing #land from #AnimalAgriculture and giving it back to #EndangeredSpecies and the earth.
The #VLM has been created for ALL OF US who want to help create a vegan world by removing land from those who harm life and to return it to #wildlife that desperately needs #habitat to survive.
The land used to farm sentient animals causes great suffering, as well as ecological destruction and species #extinction.

Meta Introduces Vision Language Models: Superior Performance and Advanced Features.


To my knowledge, this is the first example in the world of controlling the car with a Visual Language Model end-2-end! The model takes in video stream from multiple cameras and can generate language tokens and controls. Done by our team at Wayve:)
