Recent searches
Search options

#parametrization

 ️
️

Applying matrix diagonalisation in the classroom with #GeoGebra: parametrising the intersection of a sphere and plane
In collaboration with Bradley Welch
https://www.tandfonline.com/doi/full/10.1080/0020739X.2023.2233513



Pruning neural networks using Bayesian inference
https://arxiv.org/abs/2308.02451
* neural network (NN) pruning highly effective at reducing computational & memory demands of large NN
* novel approach utilizing Bayesian inference; seamlessly integrates into training procedure
* leverages the posterior probabilities of NN prior to/following pruning, enabling calculation of Bayes factors
* achieves sparsity maintains accuracy
On the curvature of the loss landscape
https://arxiv.org/abs/2307.04719
A main challenge in modern deep learning is to understand why such over-parameterized models perform so well when trained on finite data ... we consider the loss landscape as an embedded Riemannian manifold ... we focus on the scalar curvature, which can be computed analytically for our manifold ...
Manifolds: https://en.wikipedia.org/wiki/Manifold
...
Extending the Forward Forward Algorithm
https://arxiv.org/abs/2307.04205
The Forward Forward algorithm (Geoffrey Hinton, 2022-11) is an alternative to backpropagation for training neural networks (NN)
Backpropagation - the most widely successful and used optimization algorithm for training NN - has 3 important limitations ...
Hinton's paper: https://www.cs.toronto.edu/~hinton/FFA13.pdf
Discussion: https://bdtechtalks.com/2022/12/19/forward-forward-algorithm-geoffrey-hinton
...
Loss Functions and Metrics in Deep Learning. A Review
https://arxiv.org/abs/2307.02694
One of the essential components of deep learning is the choice of the loss function and performance metrics used to train and evaluate models.
This paper reviews the most prevalent loss functions and performance measurements in deep learning.
Pruning vs Quantization: Which is Better?
https://arxiv.org/abs/2307.02973
* Pruning remove weights reducing memory footprint
* Quantization (4-bit, 8-bit matrix multiplication; ...) reduces bit-width used for both weights / computation used in neural networks, leading to both predictable memory savings & reductions in the necessary compute
In most cases quantization outperforms pruning.
The bigger-is-better approach to AI is running out of road
If AI is to keep getting better, it will have to do more with less
https://www.economist.com/science-and-technology/2023/06/21/the-bigger-is-better-approach-to-ai-is-running-out-of-road
Discussion: https://news.ycombinator.com/item?id=36462282
Training Transformers with 4-bit Integers
https://arxiv.org/abs/2306.11987
... we propose a training method for transformers with matrix multiplications implemented with the INT4 arithmetic. Training with an ultra-low INT4 precision is challenging ... we carefully analyze the specific structures of activation & gradients in transformers to propose dedicated quantizers for them. For forward propagation, we identify ...


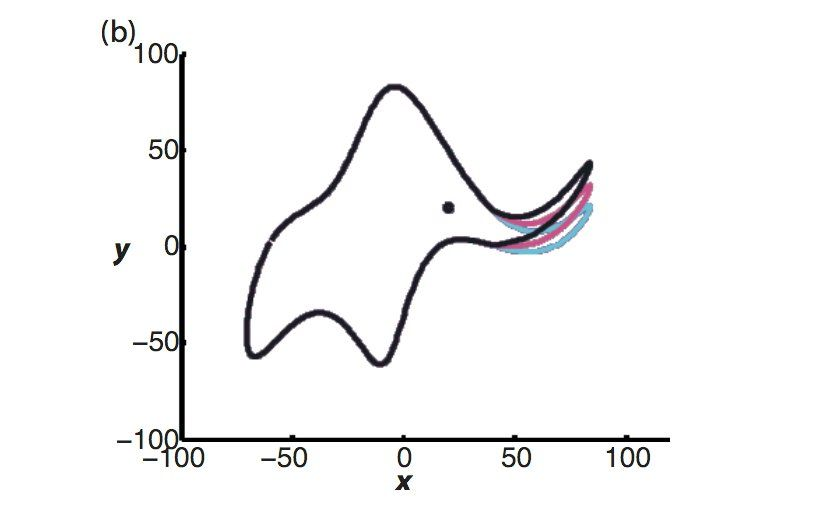
John von Neumann once claimed, "with 4 parameters, I can fit an elephant, and with 5, I can make him wiggle his trunk."
\[x(t)=\displaystyle\sum_{k=0}^\infty\left(A_k^x\cos(kt)+B_k^x\sin(kt) \right)\]
\[y(t)=\displaystyle\sum_{k=0}^\infty\left(A_k^y\cos(kt)+B_k^y\sin(kt) \right)\]
Here's a paper proving that von Neumann's claim is valid!  https://aapt.scitation.org/doi/10.1119/1.3254017
https://aapt.scitation.org/doi/10.1119/1.3254017
#Neumann #JohnVonNeumann #VonNeumann #FourierSeries #parameters #complexparameters #parametrization #mathematics #maths